
인공 지능(AI)의 최근 발전은 대중의 호기심을 사로잡았을 뿐만 아니라 이 분야의 선구자들이 항상 이해해 온 것, 즉 이러한 기술이 우리가 놀라운 일을 달성할 수 있도록 지원하는 엄청난 잠재력을 강조했습니다. 이러한 잠재력은 단순한 알고리즘 그 이상으로 확장됩니다. 이는 경제 성장, 사회 발전, 새로운 표현 방식과 연결의 새로운 시대를 열 것을 약속합니다.
Meta에서는 특히 생성 AI의 역동적인 환경 내에서 AI 개발에 대한 개방형 접근 방식을 강력하게 믿습니다. AI 모델을 공개적으로 공유함으로써 우리는 그 혜택을 사회 곳곳으로 확대합니다. 우리는 최근 Llama 2 소스를 오픈하여 이러한 대규모 언어 모델의 힘을 활용하고 기업, 신생 기업, 야심 찬 기업가 및 연구원이 도구를 활용하여 책임감 있게 아이디어를 실험하고 혁신하고 확장할 수 있도록 했습니다.
이 블로그에서는 Llama 2가 제공하는 이점을 자신의 프로젝트에서 활용할 수 있도록 Llama 2를 시작하는 5가지 단계를 살펴보겠습니다. 주요 개념, 설정 방법, 사용 가능한 리소스를 살펴보고 Llama 2를 설정하고 실행하는 단계별 프로세스를 제공합니다.
소개
Llama 2에는 7B~70B 매개변수 범위의 사전 훈련되고 미세 조정된 대규모 언어 모델을 위한 모델 가중치와 시작 코드가 포함되어 있습니다. Llama 2는 Llama 1보다 40% 더 많은 데이터를 학습했으며 컨텍스트 길이는 두 배입니다. Llama 2는 공개적으로 사용 가능한 온라인 데이터 소스를 기반으로 사전 훈련되었습니다.

Llama 2의 이미지 - Meta AI
미세 조정 모델인 Llama-2-chat은 공개적으로 사용 가능한 지침 데이터 세트와 100만 개 이상의 인간 주석을 활용하고 인간 피드백(RLHF)을 통한 강화 학습을 사용하여 안전성과 유용성을 보장합니다.
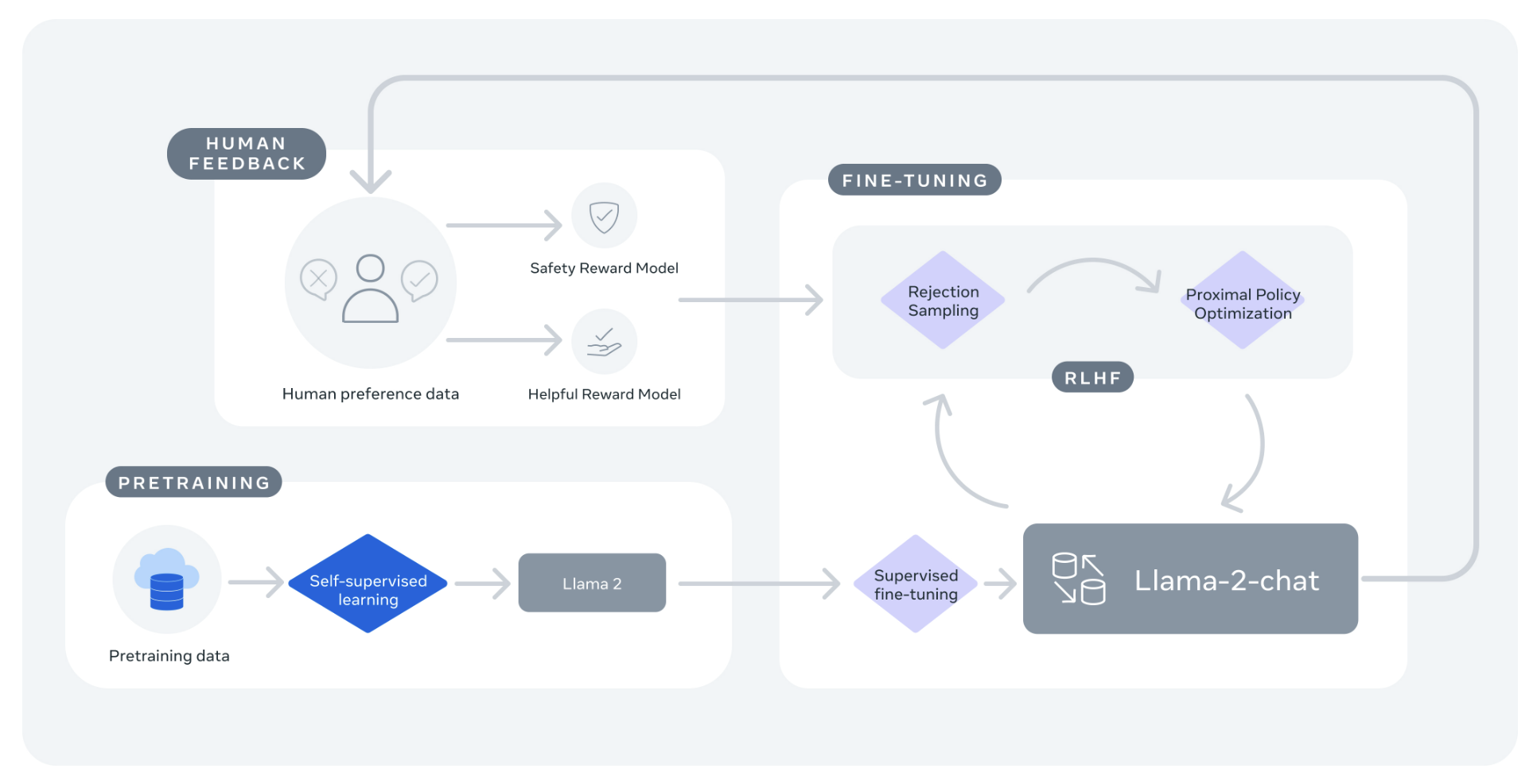
Llama 2의 이미지 - 리소스 개요 - Meta AI
Llama 2는 추론, 코딩, 숙련도, 지식 테스트를 포함한 다양한 외부 벤치마크에서 다른 개방형 언어 모델보다 성능이 뛰어납니다. 벤치마크와 비교 방법에 대해 자세히 알아보려면 당사 웹사이트 에서 자세한 내용을 확인하세요. Llama 2는 연구 및 상업적 용도로 무료로 제공됩니다.
다음 섹션에서는 Llama 2 사용을 시작하기 위해 취할 수 있는 5단계를 살펴보겠습니다. Llama 2를 로컬로 설정하는 방법에는 여러 가지가 있습니다. Llama를 쉽게 설정하고 빠르게 사용할 수 있는 방법 중 하나에 대해 논의하겠습니다. 뛰어들어보자!
라마 2 시작하기
1단계: 전제조건 및 종속성
Python을 사용하여 파이프라인을 설정하고 실행하는 스크립트를 작성하겠습니다. Python을 설치하려면 Python 웹사이트를 방문하세요 . 여기에서 OS를 선택하고 원하는 Python 버전을 다운로드할 수 있습니다.
이 예제를 실행하기 위해 Hugging Face의 변환기 와 가속 라이브러리를 사용합니다 .
pip install transformers
pip install accelerate
2단계: 모델 가중치 다운로드
우리 모델은 Llama 2 Github repo 에서 사용할 수 있습니다 . Github 저장소를 통해 모델을 다운로드하려면:
AI at Meta 웹사이트를 방문하여 라이선스에 동의하고 양식을 제출하세요. 요청이 승인되면 이메일로 미리 서명된 URL을 받게 됩니다.
Llama 2 저장소 복제
git clone https://github.com/facebookresearch/llama
download.sh 스크립트(sh download.sh)를 실행합니다. 메시지가 나타나면 이메일로 받은 미리 서명된 URL을 입력하세요.
다운로드하려는 모델 변형을 선택하세요(예: 7b-chat). 그러면 tokenizer.model과 가중치가 포함된 llama-2-7b-chat 디렉터리가 다운로드됩니다.
l을 실행하여 ln -h ./tokenizer.model ./llama-2-7b-chat/tokenizer.mode토크나이저에 대한 링크를 만듭니다. 변환에 필요합니다(다음 단계).
Hugging Face로 실행되도록 모델 가중치를 변환합니다.
TRANSFORM=`python -c "import transformers;print('/'.join(transformers.__file__.split('/')[:-1])+'/models/llama/convert_llama_weights_to_hf.py')"`
pip install protobuf && python $TRANSFORM --input_dir ./llama-2-7b-chat --model_size 7B --output_dir ./llama-2-7b-chat-hf
Hugging Face 에서는 이미 변환된 Llama 2 가중치도 제공됩니다 . Hugging Face에서 다운로드를 사용하려면 먼저 위 단계에 표시된 대로 다운로드를 요청하고 Hugging Face 계정과 동일한 이메일 주소를 사용하고 있는지 확인해야 합니다.
3단계: Python 스크립트 작성
이제 예제를 실행하는 데 사용할 새로운 Python 스크립트를 생성하겠습니다. 이 스크립트에는 모델을 로드하고 변환기를 사용하여 추론을 실행하는 데 필요한 모든 코드가 포함됩니다.
필요한 모듈 가져오기
먼저 스크립트에 다음과 같은 필수 모듈을 가져와야 합니다. LlamaForCausalLM은 Llama 2 모델 클래스이고, LlamaTokenizer는 모델이 처리할 프롬프트를 준비하고, 파이프라인은 모델 출력을 생성하기 위한 추상화이며, 토치는 PyTorch 및 사용하려는 데이터 유형을 지정합니다.
import torch
import transformers
from transformers import LlamaForCausalLM, LlamaTokenizer
모델 로드
다음으로 다운로드하고 변환한 가중치( ./llama-2-7b-chat-hf이 예에서는 에 저장됨)를 사용하여 Llama 모델을 로드합니다.
model_dir = "./llama-2-7b-chat-hf"
model = LlamaForCausalLM.from_pretrained(model_dir)
토크나이저 및 파이프라인 정의 및 인스턴스화
모델에 대한 입력이 준비되어 있는지 확인해야 합니다. 이는 모델과 관련된 토크나이저를 로드하여 수행됩니다.
동일한 모델 디렉터리에서 토크나이저를 초기화할 수 있는 다음을 스크립트에 추가하세요.
tokenizer = LlamaTokenizer.from_pretrained(model_dir)
다음으로 추론을 위해 모델을 사용하는 방법이 필요합니다. 파이프라인을 사용하면 파이프라인이 실행해야 하는 작업 유형을 지정하고( “text-generation”), 파이프라인이 예측을 위해 사용해야 하는 모델을 지정하고( model), 이 모델을 사용할 정밀도를 정의하고( torch.float16), 파이프라인이 실행되어야 하는 장치( device_map) 다양한 옵션 중에서.
스크립트에서 다음을 추가하여 예제를 실행하는 데 사용할 파이프라인을 인스턴스화합니다.
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
파이프라인 실행
이제 파이프라인이 정의되었으므로 파이프라인이 응답을 생성하기 위해 실행될 때 사용할 입력으로 일부 텍스트 프롬프트를 제공해야 합니다( sequences). 아래 예에 표시된 파이프라인은 do_sampleTrue로 설정되어 전체 어휘에 대한 확률 분포에서 다음 토큰을 선택하는 데 사용할 디코딩 전략을 지정할 수 있습니다. 이 예에서는 top_k 샘플링을 사용하고 있습니다.
을 변경하여 max_length생성된 응답의 길이를 지정할 수 있습니다.
매개변수를 1보다 크게 설정하면 num_return_sequences둘 이상의 출력을 생성할 수 있습니다.
스크립트에 다음을 추가하여 파이프라인 실행 방법에 대한 입력 및 정보를 제공합니다.
sequences = pipeline(
'I have tomatoes, basil and cheese at home. What can I cook for dinner?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=400,
)
for seq in sequences:
print(f"{seq['generated_text']}")
4단계: 모델 실행
이제 스크립트를 실행할 준비가 되었습니다. 스크립트를 저장하고 Conda 환경으로 돌아갑니다. 스크립트를 실행하려면 작성 python <name of script>.py하고 Enter를 누르십시오.
아래와 같이 모델을 다운로드하고 스크립트 실행 후 생성된 질문 및 답변과 함께 파이프라인의 단계별 진행 상황을 보여줍니다.
Llama 2-7B-chat-hf를 로컬에서 실행
이제 Llama 2를 로컬에서 설정하고 실행할 수 있습니다. 문자열 인수에 제공하여 다양한 프롬프트를 시도해 보세요. 모델을 로드할 때 모델 이름을 지정하여 다른 Llama 2 모델을 로드할 수도 있습니다. Llama 2의 작동 방식과 시작하는 데 도움이 되는 다양한 리소스에 대해 자세히 알아보려면 다음 섹션에 언급된 기타 리소스를 확인하세요.
5단계: 추가 탐색 - 리소스 및 추가 자료
Llama 2의 작동 방식, 훈련 방법 및 사용된 하드웨어에 대해 자세히 알아보려면 Llama 2: 개방형 기초 및 미세 조정된 채팅 모델 에 대한 문서를 확인하세요 . 이 문서에서는 이러한 측면을 더 자세히 다루고 있습니다.
Llama 2 모델을 로드하고 추론을 실행하는 방법에 대한 최소한의 예와 함께 모델이 작동하는 방식을 보여주는 Llama 2 Github 저장소에서 모델 소스를 가져옵니다 . 여기에서는 텍스트 완성 및 채팅 모델을 실행하기 위한 모델과 예제를 다운로드하고 설정하는 단계를 확인할 수 있습니다.
모델 아키텍처, 용도, 하드웨어 및 소프트웨어 요구 사항, 교육 데이터, 결과 및 라이선스를 다루는 모델 카드 에서 모델에 대해 자세히 알아보세요 .
미세 조정을 빠르게 시작하는 방법과 미세 조정된 모델에 대한 추론을 실행하는 방법에 대한 예제를 제공하는 llama-recipes Github 저장소를 확인하세요 .
최근 출시된 코딩용 AI 도구인 Code Llama를 확인해 보세요 . Llama 2를 기반으로 구축되었으며 코드 생성 및 논의를 위해 미세 조정된 AI 모델입니다.
당사 웹사이트를 방문하여 모델 작동 방식, 벤치마크, 기술 사양 및 자주 묻는 질문에 대해 자세히 알아보세요 .
시작부터 배포까지 다양한 개발 단계를 다루면서 책임 있는 방식으로 대형 언어 모델(LLM) 기반 제품을 구축하기 위한 모범 사례와 고려 사항을 제공하는 책임감 있는 사용 가이드를 읽어보세요 .
이 기사가 Llama 2 사용을 시작하는 데 필요한 단계를 안내하는 데 도움이 되었기를 바랍니다. 다른 오픈 소스 프로젝트를 탐색하고 이를 자신의 프로젝트에 통합하는 방법을 알아보는 향후 블로그 게시물을 계속 지켜봐 주시기 바랍니다. .
출처
https://ai.meta.com/blog/5-steps-to-getting-started-with-llama-2/
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| 머신러닝 모델 고르기? huggingface에서 한방에 해결! (0) | 2024.05.09 |
|---|---|
| OpenAI의 프롬프트 엔지니어링 가이드 (0) | 2023.12.18 |
| 메타, 초보자를 위한 'Llama2 사용법 5단계' 소개(라마2 파인튜닝 가이드) (2) | 2023.12.07 |
| 기업의 생성형 AI 프로젝트가 ‘실패’하는 4가지 이유 (7) | 2023.10.11 |
| Vision Transformer(ViT) 모델의 예측 결과 영향도 시각화 방법 (2) | 2023.09.20 |